Brand sitemap
First setup step. Crawler walks the brand domain three levels deep, classifies every URL as Core, Blogs, or Others, and feeds downstream agents.
Executive summary
Three short paragraphs explaining the feature and value.
The Brand sitemap is the first setup step in every workspace. The crawler walks the brand domain at onboarding, handles JavaScript rendered sites cleanly, and goes three levels deep. The crawl output becomes the inventory every downstream agent reads from for visibility scans, audits, and content work across the lifecycle.
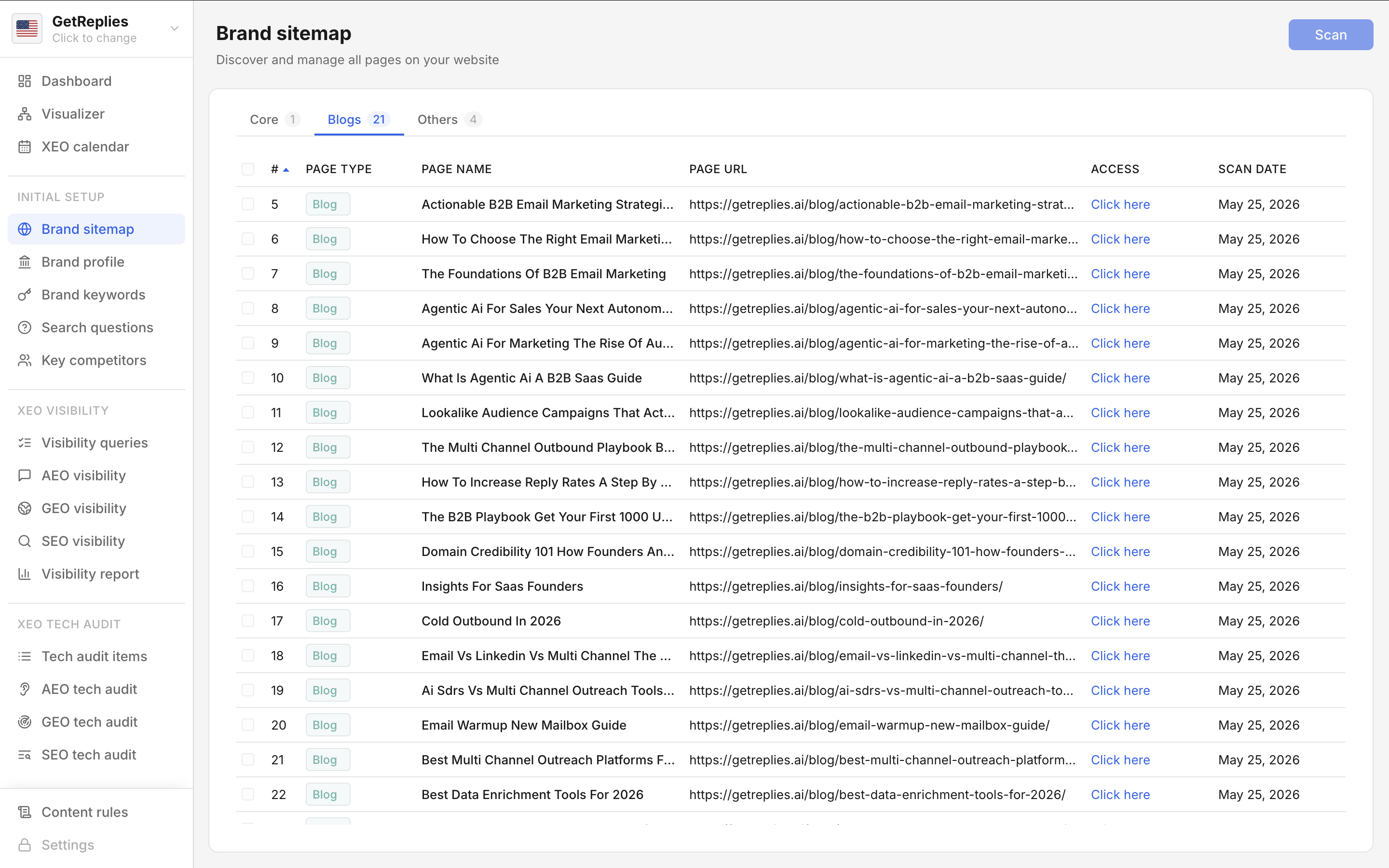
Every URL is classified into one of three buckets. Core holds the homepage, product, pricing, and other money pages. Blogs holds the insights and resource pages that drive organic traffic. Others holds legal, contact, login, and helper pages. Three tabs let users filter the entire workspace by bucket.
The classification matters because each bucket feeds different parts of the product. Core pages feed the Brand profile agent that writes the structured who we are sheet. Blogs feed Content refresh that rewrites under performing posts. Every tech audit and visibility scan can be filtered to a specific bucket on demand.
Key highlights
Five capability points teams should know about quickly.
- Crawls JavaScript rendered sites cleanly
- Three levels deep across the brand domain
- Classifies every URL into Core, Blogs, Others
- Feeds the Brand profile and Content refresh agents
- Audit and scan filters per bucket
Top FAQs
Five common questions answered for fast practical clarity.
How long does the initial crawl take?
Most brand domains complete in two to five minutes depending on site size and JavaScript rendering complexity. The crawler streams progress live so users see URL counts climbing per tab as classification completes. Sites with more than ten thousand pages may take longer; in practice the crawl caps at the first three levels.
Can I run a fresh crawl after content changes?
Yes. The Brand sitemap exposes a fresh crawl action on the Sitemap tab. New crawls update the inventory in place and flag any URLs that have been added, moved, or removed since the last walk. Downstream agents that depend on the sitemap pick up the refreshed view on their next run automatically without intervention.
What does each tab actually filter?
Core, Blogs, and Others. Core is the money pages: homepage, product, pricing, solutions, integrations. Blogs is content marketing pages: articles, guides, case studies. Others is everything else: legal, contact, careers, login, internal helper pages. The three tabs make sure scans and audits run against the right surface for the right question.
What if my site uses JavaScript heavy rendering?
The crawler renders pages with a headless browser before extracting URLs and content, so single page applications, framework rendered routes, and dynamic links are all picked up. Static HTML sites crawl faster. Either way the same classification logic runs against the rendered output of every URL the crawler visits across the brand.
Are sitemaps shared across workspaces?
No. Each workspace has its own Brand sitemap scoped to the brand domain associated with that workspace. Even when the same user owns multiple workspaces, each crawl runs independently and the sitemap stays isolated. This keeps competitive intelligence clean and matches the per workspace pricing and access model directly.